A MATHEMATICIAN'S GUIDE TO IMS METADATA
Dedicated to the research, development, implementation, and standardization of metadata for educational and research mathematics.
![]() AMS Panel discussion: Wednesday, January 19. Ballroom
Balcony A, Marriott Wardman Park Hotel. 2:15 - 5:15. Immediately followed by
American Mathematics Metadata Task Force Meeting.
AMS Panel discussion: Wednesday, January 19. Ballroom
Balcony A, Marriott Wardman Park Hotel. 2:15 - 5:15. Immediately followed by
American Mathematics Metadata Task Force Meeting.
The Overall Structure of IMS Metadata
The goal of IMS metadata is to create a standardized set of descriptors for educational and, by extension, scientific resources. These descriptors must be both machine and human readable. At a basic level, the descriptors are stored as integers, strings, boolean data, dates, and so on — the same data types commonly found in databases and spreadsheets. Instead of using a database, however, IMS metadata is stored as a tree. This has both theoretical and practical advantages but is perhaps less familiar and therefore requires some acclimatization. For machine readability, it is enough to produce a well-defined data structure whose consistency and validity can be checked by an algorithm. If we did not need to attach meaning to metadata, that would be the end of the story. But if we want to define and find resources using descriptors expressed in a natural language, then the meaning becomes essential. So does agreement upon meaning. The challenge is to find a way to translate natural language and discipline specific descriptions into a machine format that can be efficiently searched over the Internet and, at the other end, translate the results of a search back into natural language descriptions. IMS Metadata standards provide a structure for doing this. Very precise definitions and rules are required in order to make the definition work at the software level, but for the purposes of understanding how to create and interpret metadata, it suffices to understand the overall structure and a few specifics. The key is to place yourself in the role of a translator whose job it is to convert set of IMS metadata into an intelligible description of a resource. In other words, your job is to "read" the metadata. The metadata you are wish to read is given as numbers, words, and dates, so the problem is that of interpretation. You need to answer two questions: Given a descriptor, what it is describing? Given what it is describing, what does it say? In a natural language, perhaps especially in English, the meaning associated to a word depends on its context. This is also the way things work in a typical spreadsheet or database, and it is instructive to look at this more familiar example first. Consider a database of that contains information on a list of books. One of the tables in this database might be labeled Subject and contain columns labeled LCC, Sub-classification, and Grade Level (see Figure I). LCC stands for the Library of Congress Classification. If we see a value of QA in the LCC column. we can look up this value and discover that the subject is mathematics. A 241 in the Sub-classification column means that the subject within mathematics is number theory.

In this way the meaning of each cell is determined by three things: The table and column in which the cell is found. Possibly an external classification scheme, such as the Library of Congress Classification. The value of the data in the cell. The interpretation of the value of data in a cell is context-dependent. In another column in another table the number 241 might represent a price or the number of times a book has been checked out. Nonetheless, it is not hard to correctly "read" data stored in a well designed database. IMS metadata structures work in the same way, as we will now explain.
The IMS Metadata Tree.
IMS metadata are stored in trees. Each tree starts with a root. The root is implicit and represents the object being described. Next comes a set of categories. Each category represents a general type of property of the root, for example its property rights, how and by whom it was created, and its educational use. Each category has further descendents called elements which represent specific properties within each category. We will see examples below. From there on, elements can have more elements as descendants until we finally reach the leaves of the tree. The leaves contain the actual data. A basic principle is that each node is an attempt to further qualify the properties of its parent. As one descends through the tree, one progresses from the general to the specific. A path through the tree represents a narrowing of contexts until finally we reach some data. This data must be interpreted in the context defined by the path taken to reach it. To put it another way, each leaf in a tree determines a unique path from the root to that leaf. In reading a metadata tree we must first answer the question: Given a descriptor, what it is describing? The descriptors are data that reside in the leaves, and the answer to this question is that the interpretation of a piece of data is its corresponding path through the tree.
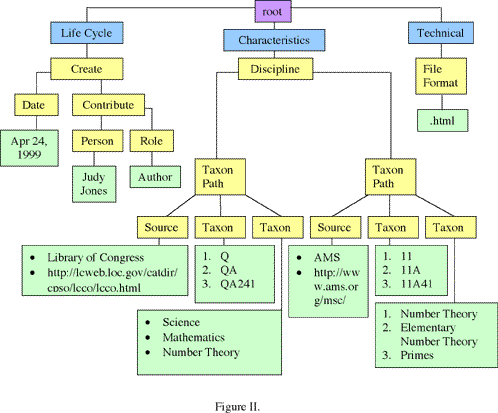
Figure II shows part of an IMS metadata tree meant to describe an entry in a digital mathematical library. The boxes are the nodes in the tree. The immediate descendents of the root are the categories. These are shaded blue. The yellow boxes are elements and the leaves are green. The text inside the leaves is data. The text inside the categories and elements are their names. We will go now through this example in detail. To start, look at the right-hand most leaf containing the data ".html". The category in which this appears is Technical, which means that we are describing technical (as in technological) properties of the root object. The element File Format tells us which technical property we are describing. The value ".html" can now be understood as meaning that the root object is written in HTML, ergo is a Web Page.
Before continuing our exploration of this example, we need to have a convenient way of writing paths through the tree. We will do this by listing the antecedent nodes in order, separated by dots. Thus the path to the leaf containing ".html" is written as Technical.FileFormat and the path to the leaf containing "Judy Jones" is written as LifeCycle.Create.Contribute.Person. These paths are called the contexts and are precisely what tell us how to interpret the data in the leaves. We can also use this notation for nodes that are not leaves. The path LifeCycle.Create, for example, refers to the second node down in the left-most path through the tree. Let us turn our attention to this node for a moment. The node LifeCycle.Create has two immediate descendants, LifeCycle.Create.Contribute and LifeCycle.Create.Date. The path name LifeCycle.Create tells us that this node represents information about the manner in which the root object was created. Therefore the leaf LifeCycle.Create.Date is the root object's creation date and the node LifeCycle.Create.Contribute contains information about a contribution to the creation of the root object. This node is not a leaf but itself has two descendants. Both descendents must qualify the same contribution. The two leaves LifeCycle.Create.Contribute.Person and LifeCycle.Create.Contribute.Role therefore combine to tell us that the contribution in question was made by a person whose role was that of an author. The value of the data in the leaf LifeCycle.Create.Contribute.Person tells us the author's name was Judy Jones.
We mentioned earlier that the interpretation of the data in a leaf is defined by its path. The path answers the question, "what does the data describe?" and the values of the data answer the question, "what does it say?" Our analysis of the node LifeCycle.Create illustrates that this generalizes to an arbitrary node in the tree. Its context tells us what the node describes and the sub-tree rooted at the node tells us the actual description.
A consequence of this is that certain elements must be included in the sub-tree rooted at a particular node. It would not make sense to specify a person as a contributor without specifying a role. In the middle part of the tree, which we will examine next, it would not make sense to specify a subject classification without saying what classification we are using.
We now turn to the two nodes whose contexts are Characteristics.Discipline.TaxonPath. A word of explanation about this vocabulary is in order. In the view of IMS metadata, a taxonomy is an external classification scheme. Examples include the Library of Congress Classification, the AMS Subject Classification, and Bloom's Taxonomy (familiar to those who study education). Taxonomies may have different parts corresponding to different points of view or properties. The Library of Congress Classification has two parts, a code and a keyword description.
The IMS metadata term TaxonPath refers to a description of the root object coming from a single taxonomy. The value of a TaxonPath node, which is to say the sub-tree rooted at that node, must include all the information necessary to understand what this description says. In our example, this consists of two pieces of information. First, we need to say which taxonomy we are using. This is done by the leaf Characteristics.Discipline.TaxonPath.Source. Notice that the data contained in this leaf is an unordered list. The elements of this list are a human readable name for the taxonomy (LCC or AMS) and a URL. The URL could at least theoretically be used by software to retrieve the taxonomy. Second, we need to use the taxonomy to describe the root object. Each piece of this description is called a Taxon. In our example, each TaxonPath has two Taxons, an ordered list of codes and an ordered list of keywords.
Again, some further explanation is needed. Taxonomies themselves are generally tree structures. Think of the LCC scheme as an example. If we specify an entry, such as QA241, this single code implies all of its parent entries. In other words, if classify the subject of a book as QA241, we automatically know that the book can be found in the library on the QA241 shelf (number theory) of the QA section (mathematics) on the floor containing Q (science). The IMS project calls this the progression from the general to the specific a taxonomic stairway. IMS specifications require the explicit inclusion of the entire stairway rather than just the last step. This builds in redundancy needed to facilitate searches. It is more practical, especially given the latency in the Internet, to be able to search directly for the keyword mathematics than to be forced to first download enough information to determine all of the keywords which imply the keyword mathematics and then to search on them.
Putting this all together, we can now interpret the nodes Characteristics.Discipline.TaxonPath. These nodes describe what we call the subject of the root object in North American English. The IMS standards are international and consequently use the word discipline instead. In our example, two independent taxonomies are used, the Library of Congress Classification and the AMS Subject Classification scheme. In each case the description of the subject matter includes a URL that points to the definition of the taxonomy, an ordered set of codes giving increasingly specific descriptions of the root object, and an ordered set of keywords organized in the same fashion. The Library of Congress Classification tells us that the Web page being described is in the area of science called mathematics and in the area of mathematics called number theory. The AMS Subject Classification tells us that the page is in the area of mathematics called number theory, in the area of number theory called elementary number theory, and in the area of elementary number theory that deals with primes.
Download the math guide!
Next page.
©by the American Mathematics Metadata Task Force. Distribution subject to Open Content License. You can reach us by using the contact form here.